Next: Collapsing categories Up: Some special topics Previous: Some special topics
![[*]](crossref.png) ) if there is association the marginal table may
be entirely misleading.
) if there is association the marginal table may
be entirely misleading.
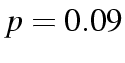 .
.
genlog freq size mode /print=est/plot=none /design = freq size mode mode*size.and then collapse the table:
genlog freq mode /print=est/plot=none /design = freq mode.We find the fit changing from 132.9 for 8 df to 123.9 for 2 df,
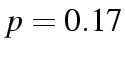 . Not only does the fit not improve, but we are facing the
opposite problem of sparsity, a table that is too small to fit
interesting tables to (only
. Not only does the fit not improve, but we are facing the
opposite problem of sparsity, a table that is too small to fit
interesting tables to (only 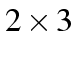 ). Therefore we retain
size as a classifying variable.
). Therefore we retain
size as a classifying variable.
 |
| ||||||||