This blog describes an ongoing research project which uses both survey data (from the European Social Survey) and web-scraping (of Google News data via SerpApi) to understand how Irish attitudes to immigration have changed over the last two decades.
The Republic of Ireland has undergone significant social transformations in the last few years, and one of the reasons for this transformation is immigration. Up until now, survey data and questionnaires from repositories like the Central Statistics Office (CSO), Eurobarometer, European Social Survey (ESS), and other public data sources have been used for different observations and analyses for studying societal attitudes. These sources provide first-order data that are gathered through efficient sampling strategies, and they update their data regularly, highlighting different topics and subtopics for that particular year.
However, survey data on immigration attitudes can be affected by social desirability bias, potentially masking negative views. This was justified by Creighton and colleagues (2022), the computational sociology group working at UCD, and they highlighted Web scraping offers unfiltered insights. The attempt from ESS to gather contextual data using approaches like Event data creation and documenting media claims lead us to new methodologies to analyze societal attitudes collectively.

Image Courtesy: The Irish TimesKey theories, concepts, and previous studies
Public perceptions of immigrants in Ireland have changed over time. Currently, attitudes to immigration in Ireland are among the most positive in Europe (Kumar et. al 2022). Irish sentiments towards immigrants were highly favourable between 2002 and 2006. Ireland’s own experience with mass emigration has shaped public attitudes, improving values like hospitality and openness. There has been a shift in attitude during the Recession and it was lower than the Western European average (McGinnity et. al 2018). The global financial crisis of 2008 had a great impact on Ireland’s economy. During that time there have been potential competitions with immigrants, and it led to some tension in the job market. Until 2010 the social attitude wasn’t favourable for the immigrants. But it started becoming positive again in 2012, 2014 and 2018. In the year 2018, 66% of Irish respondents held a positive view towards immigration (Kumar et al. 2022). In the last 5 years, the approach to immigration and integration has started seeing both progress and challenges. Covid-19 had a major impact on immigration and access towards health services, citizenship, political opportunities, and justice. A significant minority of people did not align with the openness of Irish society, and the general public’s attitudes regarding immigration and integration were not really positive. (Pollak 2021).
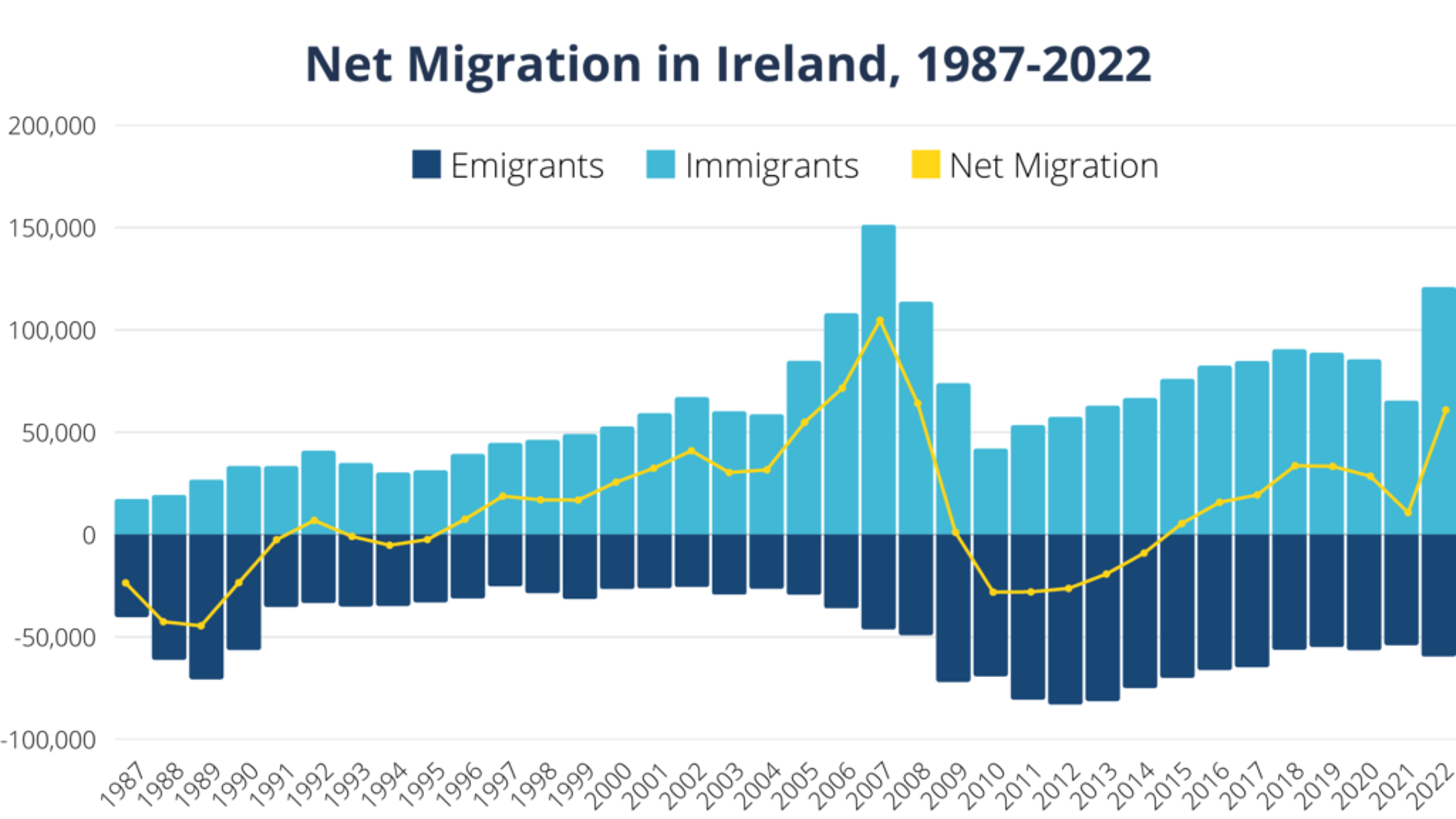
@Central Statistics Office, Ireland
https://data.cso.ie/table/PEA15Along with the Survey data the ESS attempted to gather contextual data using an approach called “Event data collection”. The challenges behind this approach were the ambiguity around the definition of an event and its viability. After that, a different method of “the systematic cross-national recording of events” was developed to document media claims. The methodology for both data collection and analysis presented difficulties, though, as this approach was very labour-intensive and finally, this had to be discontinued. Efforts were made in 2018 to create tools that would allow media data to be semi-automatically coded using Natural Language Processing (NLP) techniques such as topic modelling; however, these efforts had to be abandoned because of the lack of technical stack (Monitoring National Contexts n.d.)
Frey (2020) examined the impact of the 2015 New Year’s Eve sexual assaults in Germany on the frequency and distribution of intergroup conflict using logistic regression modelling where the data collection was through web scraping. He used textual information on each attack, including the type of offence, location, and date of each incident. Kozlowski et. al 2019 used word embedding models to analyse cultural categories and associations, particularly focusing on the multidimensional nature of the social class.
Data
This research will utilise both quantitative and qualitative data for analysis.
- Twenty years of European Social Survey (ESS) cross-sectional data (2002 to 2022) on attitudes to equality and human rights issues in Ireland
- Twenty years of news media data on selected ESS questions representing societal attitudes scraped from Google News using data providers.
Methods and approaches
The ESS data has a vast number of questions (577 questions) for the theme “Race, Ethnicity and Nationality”. From the set of questions on the theme of societal attitudes, 6 questions with cross-sectional data were identified.
| Variable | Question | Reponse | Response Detailed |
|---|---|---|---|
| Imsmetn | Allow many/few immigrants of same race/ethnic group as majority | Ordinal | Allow many, some, few, none |
| Imdfetn | Allow many/few immigrants of different race/ethnic group from majority | Ordinal | Allow many, some, few, none |
| Impcntr | Allow many/few immigrants from poorer countries outside Europe | Ordinal | Allow many, some, few, none |
| Imbgeco | Immigration bad or good for country’s economy | Ratio | 0-10 scale |
| Imueclt | Country’s cultural life undermined or enriched by immigrants | Ratio | 0-10 scale |
| imwbcnt | Immigrants make country worse or better place to live | Ratio | 0-10 scale |
Table-1, ESS Questions and its scopeAnalysis of this data offers an understanding of societal change in attitudes over 20 years. While there appears to be stability in respondents’ opinions on immigration, minor variations suggest potential shifts in public sentiment over time and further analysis could identify the underlying factors driving these fluctuations and assess the impact of external events or socio-political contexts on attitudes towards immigration.
To perform Qualitative data analysis, I make use of Natural Language Processing techniques (NLP) and Web Scraping over news media data. NLP is an interdisciplinary field concerned with the interactions between computers and human natural languages (e.g: English) — speech or text. NLP-powered software helps us in our daily lives in various ways, for example:
- Personal assistants: Siri, Cortana, and Google Assistant.
- Auto-complete: In search engines (e.g: Google, Bing).
- Spell checking: Almost everywhere, in your browser, your IDE (e.g: Visual Studio), desktop apps (e.g: Microsoft Word).
- Machine Translation: Google Translate.
- Chatbots: Open AI’s ChatGPT, Google BARD etc.
In this Research, data from Google News is used. Google News is one of the world’s largest financial supporters of journalism and it’s been more than 20 years with the news industry. It provides relevant news information about events and incidents. Google News is openly available and with manual queries and searches it’s possible to retrieve data for a specific period and location.
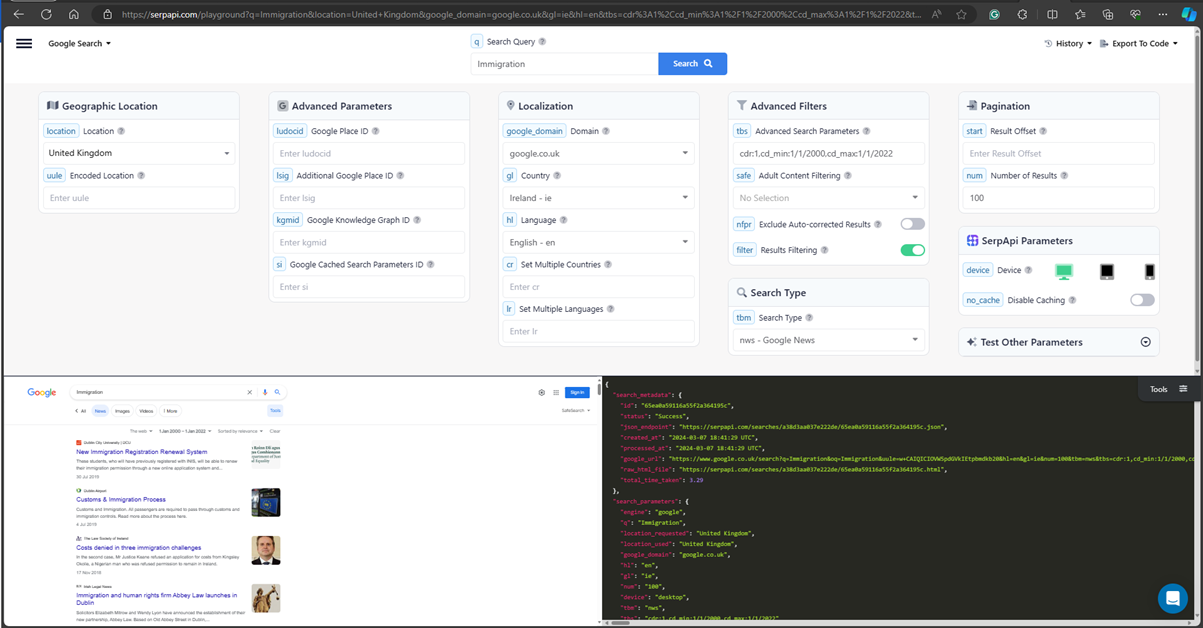
To access this search engine data and automate the data collection process efficiently we use SerpApi. SerpApi offers organic results with location-specific options, and it enables customisable data filtering. It returns structured results with URLs, titles, descriptions, published dates, and publisher details in a JSON format. Here is an example code snippet calling the SerpApi for a custom search query. It also comes with a Legal US shield for crawling and parsing of public data protected by the First Amendment of the United States Constitution.
SerpApi also offers an interactive playground on its website to test out the search queries.
For each of the six questions, a set of keyword queries is used to call SerpApi and store the resulting URLs. These URLs are then passed to a custom Web Scrapper module built using Python Libraries, which returns other important metadata. This process is repeated for 20 years, from 2002 to 2022, and the resulting data is tabulated for analysis.
The scraped unstructured raw data will be prioritised based on the relevance of the question using the keywords associated with it. The keywords are transformed into embeddings which would be further used by the transformer models such as BERT, and GPT-3 to rank the data based on relevance. The data with maximum relevance to the topic will be further analysed using NLP techniques like Sentiment Analysis, Topic Modelling, Question Answering etc. In the final stage of the process, the collected data is integrated with the ESS data to construct a comprehensive narrative outlining the survey results. The AI results undergo rigorous manual validation during this phase to ensure accuracy and reliability. Given the domain-specific nature of the research analysis, where nuances and context are important, the research adopts a human-centric approach to leveraging AI
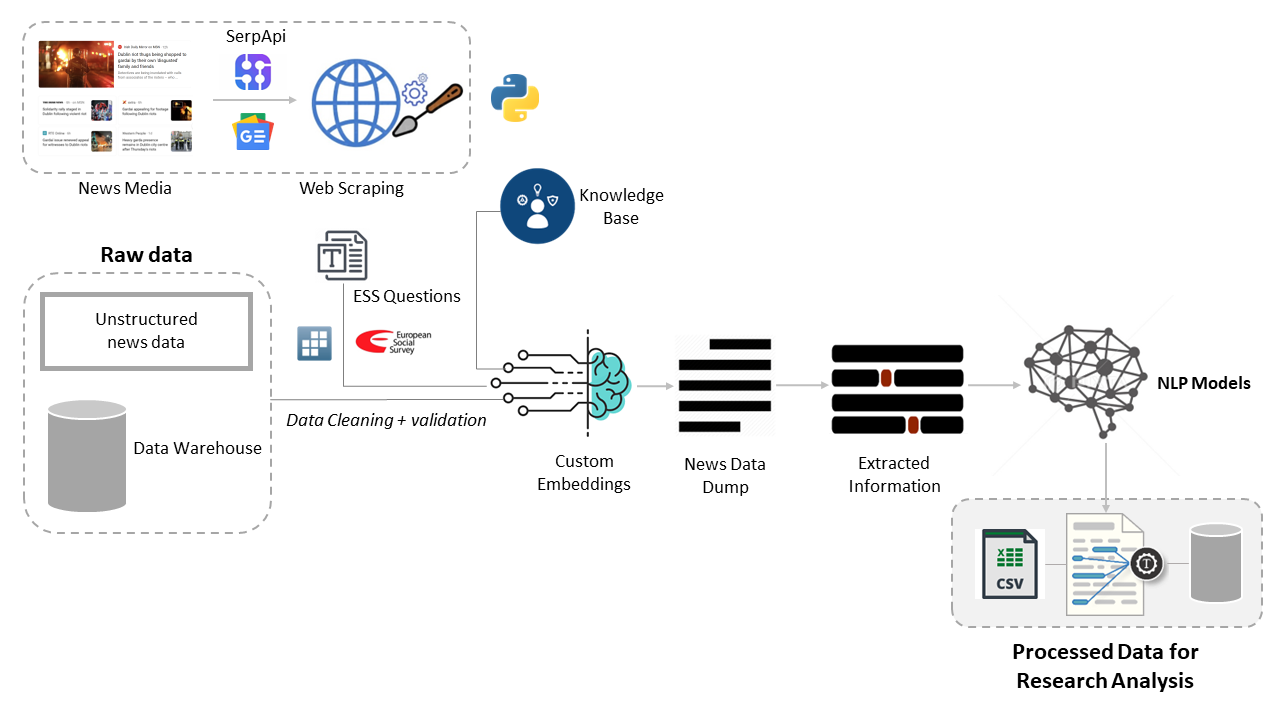
High Level ArchitectureImplications and Significance
The sociology of immigration attitudes often intersects with discussions of culture and economy. It is important to understand how cultural perceptions of immigration, such as notions of national identity and belonging, intersect with economic factors like job competition and public resources.
This Research contributes to policy debates about immigrant integration in Ireland by providing an in-depth analysis of news media data. It draws on new methods aimed at producing a novel dataset matching news and survey data, with which sociologists can further explore broader societal change in immigrant attitudes over time.

Image Courtesy: Remix News