Everyone knows that Midwinter’s Day, the day of the Winter Solstice, is the shortest day of the year. I think about this a lot, mostly every December/March/June/September (also around DST time changes). A few years ago I discovered the R “suncalc” package. It’s full of interesting astronomical functions, and can show the timing of sunrise, sunset, solar noon and a whole lot of other things, for any date and location. So I’ve been playing with it to help me understand what’s going on.
library(suncalc) library(ggplot2) data = getSunlightTimes(date = as.Date(seq(0,32), origin="2023-12-08"), lat=52.7, lon=-8.6) data$daylength = data$sunset - data$sunrise ggplot() + geom_point(data=data, aes(x=as.Date(sunrise), y=daylength))
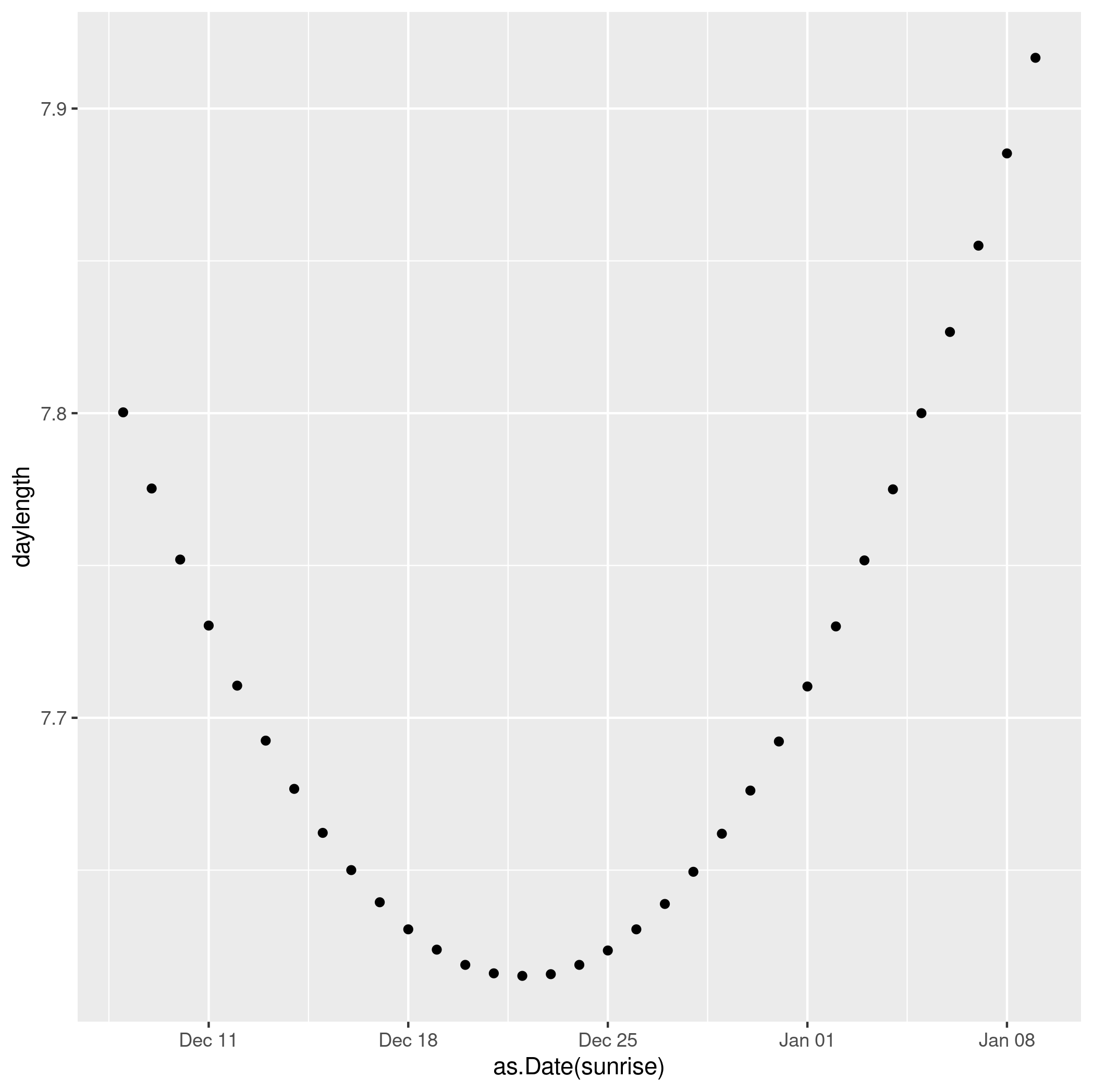
We see clearly that the shortest day in 2023 was Dec 22 (the exact solstice moment was 22 Dec, 03:27).
But the earliest sunset doesn’t actually happen then. It actually happened a few days earlier, Dec 15.
Continue reading The shortest day and the earliest sunset